

- Meta is introducing Velox, an open supply unified execution engine aimed toward accelerating knowledge administration programs and streamlining their improvement.
- Velox is underneath energetic improvement. Experimental outcomes from our paper revealed on the Worldwide Convention on Very Massive Knowledge Bases (VLDB) 2022 present how Velox improves effectivity and consistency in knowledge administration programs.
- Velox helps consolidate and unify knowledge administration programs in a fashion we consider will likely be of profit to the trade. We’re hoping the bigger open supply neighborhood will be a part of us in contributing to the venture.
Meta’s infrastructure performs an necessary function in supporting our services. Our knowledge infrastructure ecosystem consists of dozens of specialised knowledge computation engines, all targeted on completely different workloads for a wide range of use circumstances starting from SQL analytics (batch and interactive) to transactional workloads, stream processing, knowledge ingestion, and extra. Just lately, the fast development of synthetic intelligence (AI) and machine studying (ML) use circumstances inside Meta’s infrastructure has led to further engines and libraries focused at characteristic engineering, knowledge preprocessing, and different workloads for ML coaching and serving pipelines.
Nonetheless, regardless of the similarities, these engines have largely developed independently. This fragmentation has made sustaining and enhancing them troublesome, particularly contemplating that as workloads evolve, the {hardware} that executes these workloads additionally adjustments. In the end, this fragmentation leads to programs with completely different characteristic units and inconsistent semantics — lowering the productiveness of knowledge customers that must work together with a number of engines to complete duties.
With a purpose to tackle these challenges and to create a stronger, extra environment friendly knowledge infrastructure for our personal merchandise and the world, Meta has created and open sourced Velox. It’s a novel, state-of-the-art unified execution engine that goals to hurry up knowledge administration programs in addition to streamline their improvement. Velox unifies the frequent data-intensive elements of knowledge computation engines whereas nonetheless being extensible and adaptable to completely different computation engines. It democratizes optimizations that have been beforehand applied solely in particular person engines, offering a framework during which constant semantics will be applied. This reduces work duplication, promotes reusability, and improves total effectivity and consistency.
Velox is underneath energetic improvement, nevertheless it’s already in numerous levels of integration with greater than a dozen knowledge programs at Meta, together with Presto, Spark, and PyTorch (the latter via an information preprocessing library referred to as TorchArrow), in addition to different inside stream processing platforms, transactional engines, knowledge ingestion programs and infrastructure, ML programs for characteristic engineering, and others.
Because it was first uploaded to GitHub, the Velox open supply venture has attracted greater than 150 code contributors, together with key collaborators equivalent to Ahana, Intel, and Voltron Knowledge, in addition to numerous tutorial establishments. By open-sourcing and fostering a neighborhood for Velox, we consider we are able to speed up the tempo of innovation within the knowledge administration system’s improvement trade. We hope extra people and firms will be a part of us on this effort.
An summary of Velox
Whereas knowledge computation engines could seem distinct at first, they’re all composed of the same set of logical elements: a language entrance finish, an intermediate illustration (IR), an optimizer, an execution runtime, and an execution engine. Velox offers the constructing blocks required to implement execution engines, consisting of all data-intensive operations executed inside a single host, equivalent to expression analysis, aggregation, sorting, becoming a member of, and extra — additionally generally known as the info aircraft. Subsequently, Velox expects an optimized plan as enter and effectively executes it utilizing the assets obtainable within the native host.
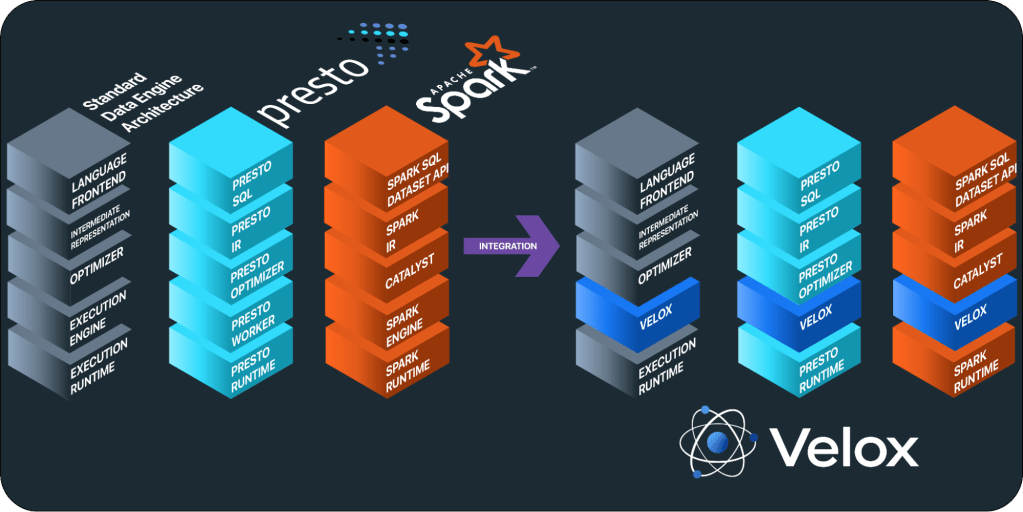
Velox leverages quite a few runtime optimizations, equivalent to filter and conjunct reordering, key normalization for array and hash-based aggregations and joins, dynamic filter pushdown, and adaptive column prefetching. These optimizations present optimum native effectivity given the obtainable information and statistics extracted from incoming batches of knowledge. Velox can be designed from the bottom as much as effectively help advanced knowledge varieties resulting from their ubiquity in trendy workloads, and therefore extensively depends on dictionary encoding for cardinality-increasing and cardinality-reducing operations equivalent to joins and filtering, whereas nonetheless offering quick paths for primitive knowledge varieties.
The primary elements offered by Velox are:
- Sort: a generic sort system that permits builders to signify scalar, advanced, and nested knowledge varieties, together with structs, maps, arrays, features (lambdas), decimals, tensors, and extra.
- Vector: an Apache Arrow–suitable columnar reminiscence format module supporting a number of encodings, equivalent to flat, dictionary, fixed, sequence/RLE, and body of reference, along with a lazy materialization sample and help for out-of-order end result buffer inhabitants.
- Expression Eval: a state-of-the-art vectorized expression analysis engine constructed based mostly on vector-encoded knowledge, leveraging methods equivalent to frequent subexpression elimination, fixed folding, environment friendly null propagation, encoding-aware analysis, dictionary peeling, and memoization.
- Capabilities: APIs that can be utilized by builders to construct customized features, offering a easy (row by row) and vectorized (batch by batch) interface for scalar features and an API for combination features.
- A operate package deal suitable with the favored PrestoSQL dialect can be offered as a part of the library.
- Operators: implementation of frequent SQL operators equivalent to TableScan, Mission, Filter, Aggregation, Alternate/Merge, OrderBy, TopN, HashJoin, MergeJoin, Unnest, and extra.
- I/O: a set of APIs that permits Velox to be built-in within the context of different engines and runtimes, equivalent to:
- Connectors: allows builders to specialize knowledge sources and sinks for TableScan and TableWrite operators.
- DWIO: an extensible interface offering help for encoding/decoding fashionable file codecs equivalent to Parquet, ORC, and DWRF.
- Storage adapters: a byte-based extensible interface that permits Velox to hook up with storage programs equivalent to Tectonic, S3, HDFS, and extra.
- Serializers: a serialization interface concentrating on community communication the place completely different wire protocols will be applied, supporting PrestoPage and Spark’s UnsafeRow codecs.
- Useful resource administration: a group of primitives for dealing with computational assets, equivalent to CPU and reminiscence administration, spilling, and reminiscence and SSD caching.
Velox’s fundamental integrations and experimental outcomes
Past effectivity positive factors, Velox offers worth by unifying the execution engines throughout completely different knowledge computation engines. The three hottest integrations are Presto, Spark, and TorchArrow/PyTorch.
Presto — Prestissimo
Velox is being built-in into Presto as a part of the Prestissimo venture, the place Presto Java employees are changed by a C++ course of based mostly on Velox. The venture was initially created by Meta in 2020 and is underneath continued improvement in collaboration with Ahana, together with different open supply contributors.
Prestissimo offers a C++ implementation of Presto’s HTTP REST interface, together with worker-to-worker alternate serialization protocol, coordinator-to-worker orchestration, and standing reporting endpoints, thereby offering a drop-in C++ alternative for Presto employees. The primary question workflow consists of receiving a Presto plan fragment from a Java coordinator, translating it right into a Velox question plan, and handing it off to Velox for execution.
We performed two completely different experiments to discover the speedup offered by Velox in Presto. Our first experiment used the TPC-H benchmark and measured near an order of magnitude speedup in some CPU-bound queries. We noticed a extra modest speedup (averaging 3-6x) for shuffle-bound queries.
Though the TPC-H dataset is an ordinary benchmark, it’s not consultant of actual workloads. To discover how Velox may carry out in these situations, we created an experiment the place we executed manufacturing site visitors generated by a wide range of interactive analytical instruments discovered at Meta. On this experiment, we noticed a mean of 6-7x speedups in knowledge querying, with some outcomes growing speedups by over an order of magnitude. You may be taught extra concerning the particulars of the experiments and their leads to our research paper.
Prestissimo’s codebase is accessible on GitHub.
Spark — Gluten
Velox can be being built-in into Spark as a part of the Gluten project created by Intel. Gluten permits C++ execution engines (equivalent to Velox) for use inside the Spark setting whereas executing Spark SQL queries. Gluten decouples the Spark JVM and execution engine by making a JNI API based mostly on the Apache Arrow knowledge format and Substrait question plans, thus permitting Velox for use inside Spark by merely integrating with Gluten’s JNI API.
Gluten’s codebase is accessible on GitHub.
TorchArrow
TorchArrow is a dataframe Python library for knowledge preprocessing in deep studying, and a part of the PyTorch venture. TorchArrow internally interprets the dataframe illustration right into a Velox plan and delegates it to Velox for execution. Along with converging the in any other case fragmented area of ML knowledge preprocessing libraries, this integration permits Meta to consolidate execution-engine code between analytic engines and ML infrastructure. It offers a extra constant expertise for ML finish customers, who’re generally required to work together with completely different computation engines to finish a specific job, by exposing the identical set of features/UDFs and making certain constant habits throughout engines.
TorchArrow was just lately launched in beta mode on GitHub.
The way forward for database system improvement
Velox demonstrates that it’s potential to make knowledge computation programs extra adaptable by consolidating their execution engines right into a single unified library. As we proceed to combine Velox into our personal programs, we’re dedicated to constructing a sustainable open supply neighborhood to help the venture in addition to to hurry up library improvement and trade adoption. We’re additionally keen on persevering with to blur the boundaries between ML infrastructure and conventional knowledge administration programs by unifying operate packages and semantics between these silos.
Wanting on the future, we consider Velox’s unified and modular nature has the potential to be useful to industries that make the most of, and particularly people who develop, knowledge administration programs. It is going to enable us to companion with {hardware} distributors and proactively adapt our unified software program stack as {hardware} advances. Reusing unified and extremely environment friendly elements may also enable us to innovate quicker as knowledge workloads evolve. We consider that modularity and reusability are the way forward for database system improvement, and we hope that knowledge firms, academia, and particular person database practitioners alike will be a part of us on this effort.
In-depth documentation about Velox and these elements will be discovered on our website and in our analysis paper “Velox: Meta’s unified execution engine.”
Acknowledgements
We want to thank all contributors to the Velox venture. A particular thank-you to Sridhar Anumandla, Philip Bell, Biswapesh Chattopadhyay, Naveen Cherukuri, Wei He, Jiju John, Jimmy Lu, Xiaoxuang Meng, Krishna Pai, Laith Sakka, Bikramjeet Vigand, Kevin Wilfong from the Meta group, and to numerous neighborhood contributors, together with Frank Hu, Deepak Majeti, Aditi Pandit, and Ying Su.






