- We’ve made structure modifications to Meta’s occasion pushed asynchronous computing platform which have enabled straightforward integration with a number of event-sources.
- We’re sharing our learnings from dealing with varied workloads and find out how to sort out commerce offs made with sure design selections in constructing the platform.
Asynchronous computing is a paradigm the place the person doesn’t anticipate a workload to be executed instantly; as an alternative, it will get scheduled for execution someday within the close to future with out blocking the latency-critical path of the applying. At Meta, we have now constructed a platform for serverless asynchronous computing that’s supplied as a service for different engineering groups. They register asynchronous features on the platform after which submit workloads for execution by way of our SDK. The platform executes these workloads within the background on a big fleet of employees and gives further capabilities comparable to load balancing, charge limiting, quota administration, downstream safety and lots of others. We seek advice from this infrastructure internally as “Async tier.”
At present we assist myriad totally different buyer use circumstances which lead to multi-trillion workloads being executed every day.
There may be already an amazing article from 2020 that dives into the main points of the structure of Async tier, the options it supplied, and the way these options may very well be utilized at scale. Within the following materials we are going to focus extra on design and implementation elements and clarify how we re-architected the platform to allow five-fold progress over the previous two years.
Basic high-level structure
Any asynchronous computing platform consists of the next constructing blocks:
- Ingestion and storage
- Transport and routing
- Computation
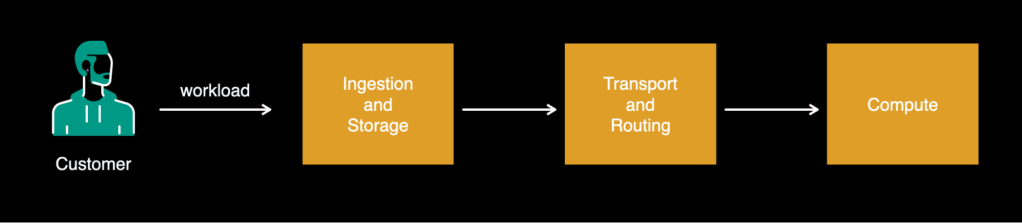
Ingestion and storage
Our platform is accountable for accepting the workloads and storing them for execution. Right here, each latency and reliability are important: This layer should settle for the workload and reply again ASAP, and it should retailer the workload reliably all the way in which to profitable execution.
Transport and routing
This offers with transferring the enough variety of workloads from storage into the computation layer, the place they are going to be executed. Sending insufficient numbers will underutilize the computation layer and trigger an pointless processing delay, whereas sending too many will overwhelm the machines accountable for the computation and may trigger failures. Thus, we outline sending the right quantity as “flow-control.”
This layer can be accountable for sustaining the optimum utilization of sources within the computation layer in addition to further options comparable to cross-regional load balancing, quota administration, charge limiting, downstream safety, backoff and retry capabilities, and lots of others.
Computation
This normally refers to particular employee runtime the place the precise perform execution takes place.
Again in 2020
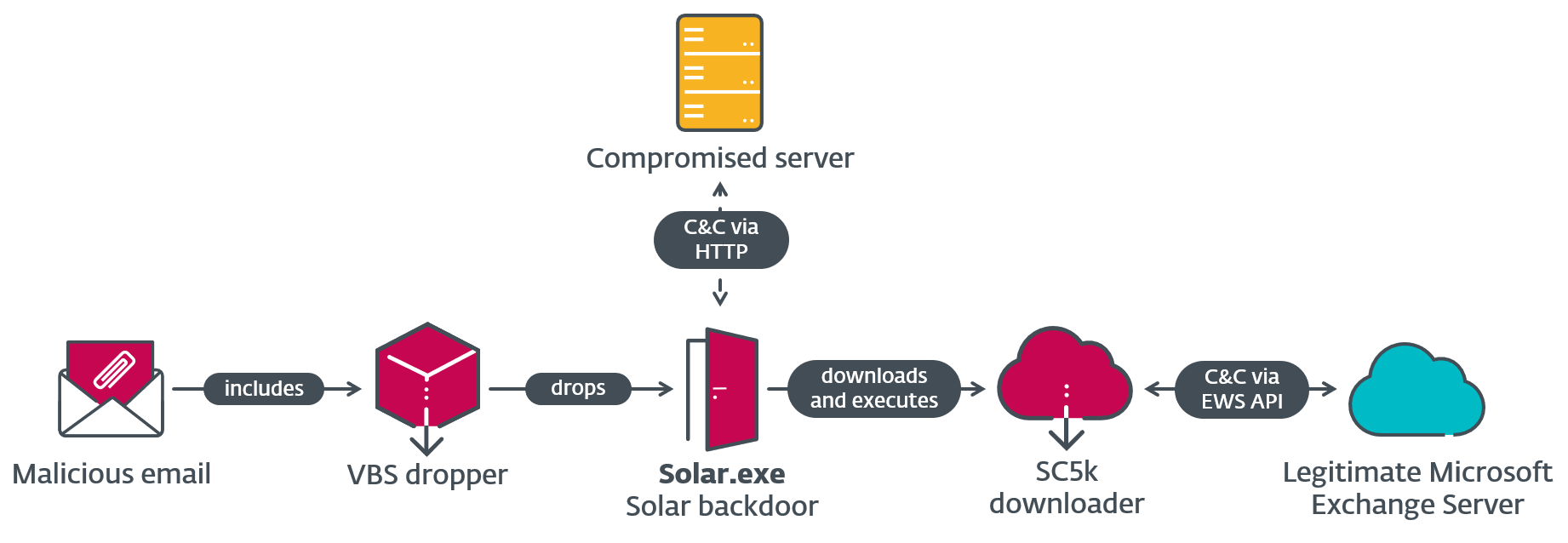
Up to now, Meta constructed its personal distributed precedence queue, equal to a few of the queuing options supplied by public cloud suppliers. It’s known as the Fb Ordered Queuing Service (because it was constructed when the corporate was known as Fb), and has a well-known acronym: FOQS. FOQS is important to our story, as a result of it comprised the core of the ingestion and storage parts.
Fb Ordered Queuing Service (FOQS)
FOQS, our in-house distributed precedence queuing service, was developed on high of MySQL and gives the flexibility to place gadgets within the queue with a timestamp, after which they need to be accessible for consumption as an enqueue operation. The accessible gadgets will be consumed later with a dequeue operation. Whereas dequeuing, the patron holds a lease on an merchandise, and as soon as the merchandise is processed efficiently, they “ACK” (acknowledge) it again to FOQS. In any other case, they “NACK” (NACK means unfavourable acknowledgement) the merchandise and it turns into accessible instantly for another person to dequeue. The lease also can expire earlier than both of those actions takes place, and the merchandise will get auto-NACKed owing to a lease timeout. Additionally, that is non-blocking, that means that prospects can take a lease on subsequently enqueued, accessible gadgets despite the fact that the oldest merchandise was neither ACKed nor NACKed. There’s already an amazing article on the topic in case you are thinking about diving deeply into how we scaled FOQS.
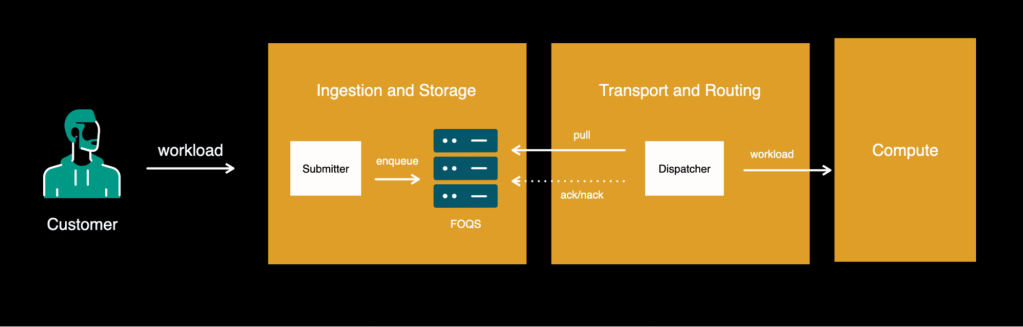
Async tier leveraged FOQS by introducing a light-weight service, known as “Submitter,” that prospects might use to submit their workloads to the queue. Submitter would do fundamental validation / overload safety and enqueue this stuff into FOQS. The transport layer consisted of a element known as “Dispatcher.” This pulled gadgets from FOQS and despatched them to the computation layer for execution.
Challenges
Rising complexity of the system
Over time we began to see that the dispatcher was taking an increasing number of accountability, rising in dimension, and turning into nearly a single place for all the brand new options and logic that the crew is engaged on. It was:
- Consuming gadgets from FOQS, managing their lifecycle.
- Defending FOQS from overload by adaptively adjusting dequeue charges.
- Offering all common options comparable to charge limiting, quota administration, workload prioritization, downstream safety.
- Sending workloads to a number of employee runtimes for execution and managing job lifecycle.
- Offering each native and cross-regional load balancing and movement management.
Consolidating a major quantity of logic in a single element finally made it arduous for us to work on new capabilities in parallel and scale the crew operationally.
Exterior knowledge sources
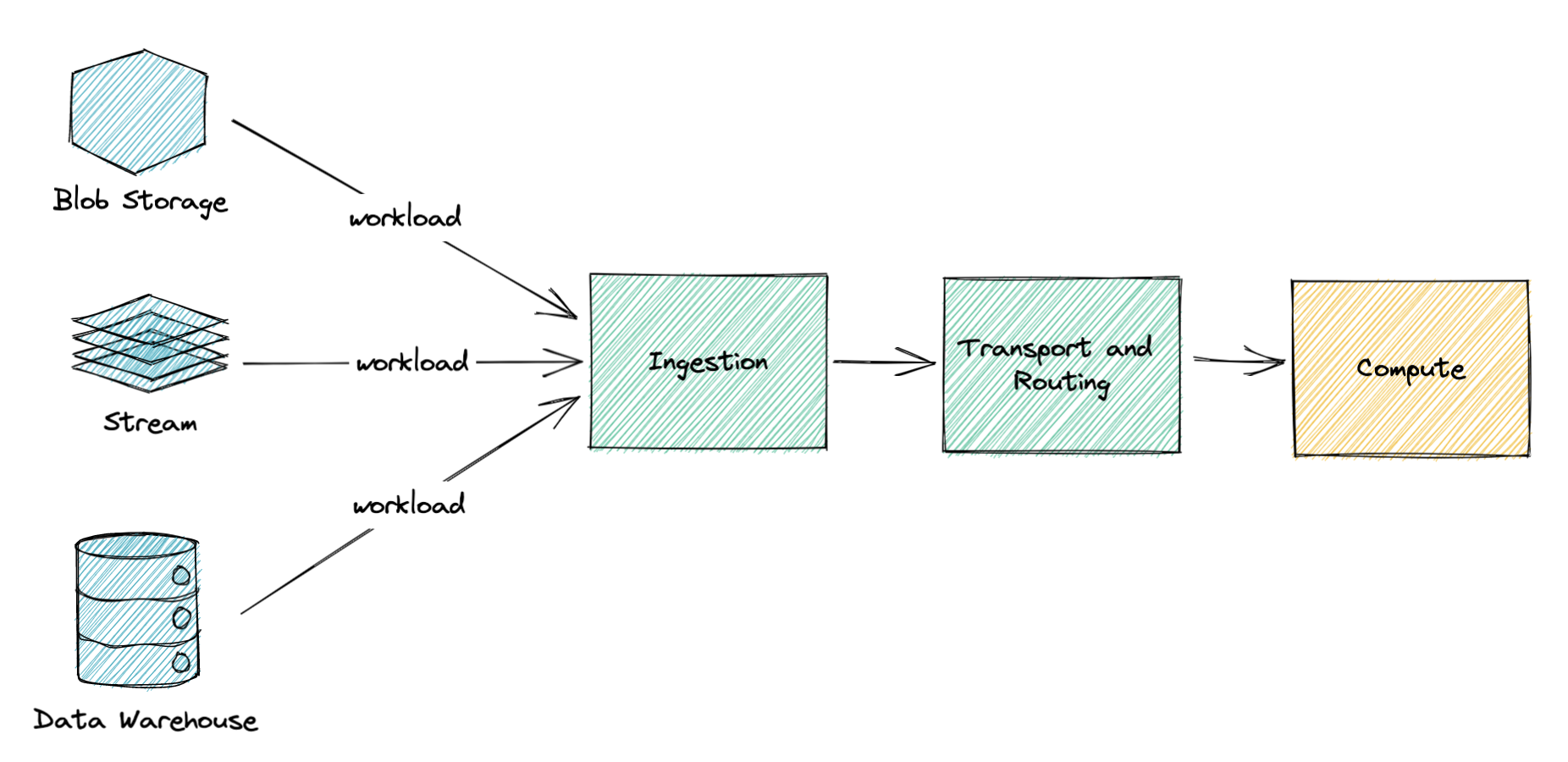
On the similar time we began to see an increasing number of requests from prospects who wish to execute their workloads primarily based on knowledge that’s already saved in different techniques, comparable to stream, knowledge warehouse, blob storage, pub sub queues, or many others. Though it was doable to do within the present system, it was coming together with sure downsides.
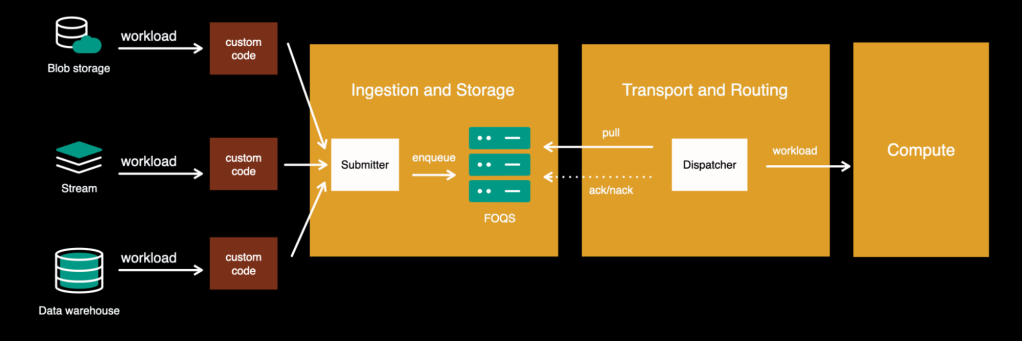
The restrictions within the above structure are:
- Prospects needed to write their very own options to learn knowledge from the unique storage and submit it to our platform by way of Submitter API. It was inflicting recurrent duplicate work throughout a number of totally different use circumstances.
- Information all the time needed to be copied to FOQS, inflicting main inefficiency when occurring at scale. As well as, some storages have been extra appropriate for explicit varieties of knowledge and cargo patterns than others. For instance, the price of storing knowledge from high-traffic streams or massive knowledge warehouse tables within the queue will be considerably greater than protecting it within the authentic storage.
Re-architecture
To unravel the above issues, we needed to break down the system into extra granular parts with clear duties and add first-class assist for exterior knowledge sources.
Our re-imagined model of Async tier would appear to be this:
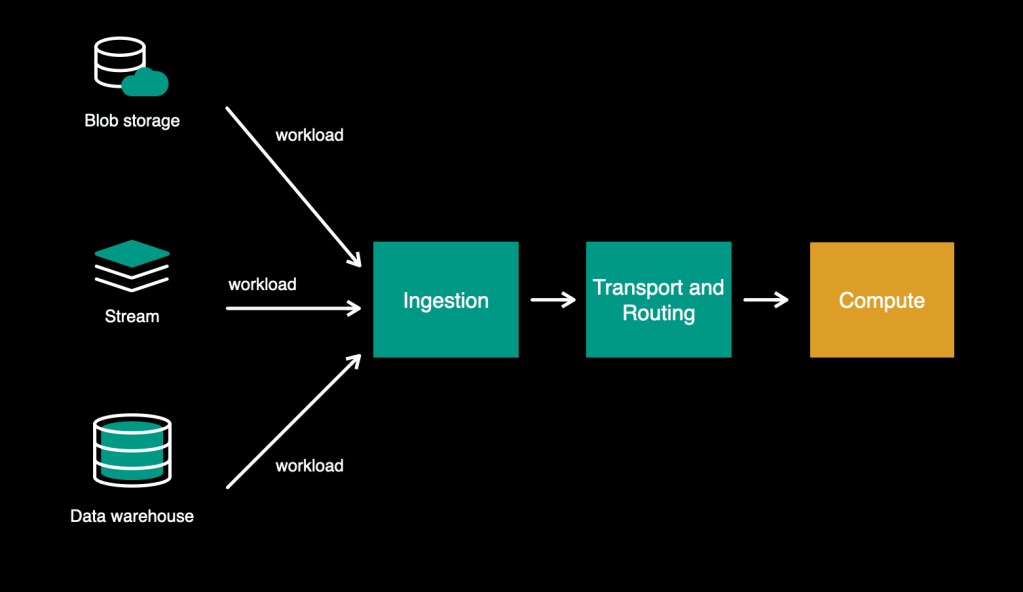
Generic transport layer
Within the previous system, our transport layer consisted of the dispatcher, which pulled workloads from FOQS. As step one on the trail of multi-source assist, we decoupled the storage studying logic from the transport layer and moved it upstream. This left the transport layer as a data-source-agnostic element accountable for managing the execution and offering a compute-related set of capabilities comparable to charge limiting, quota administration, load balancing, and so on. We name this “scheduler”—an impartial service with a generic API.
Studying workloads
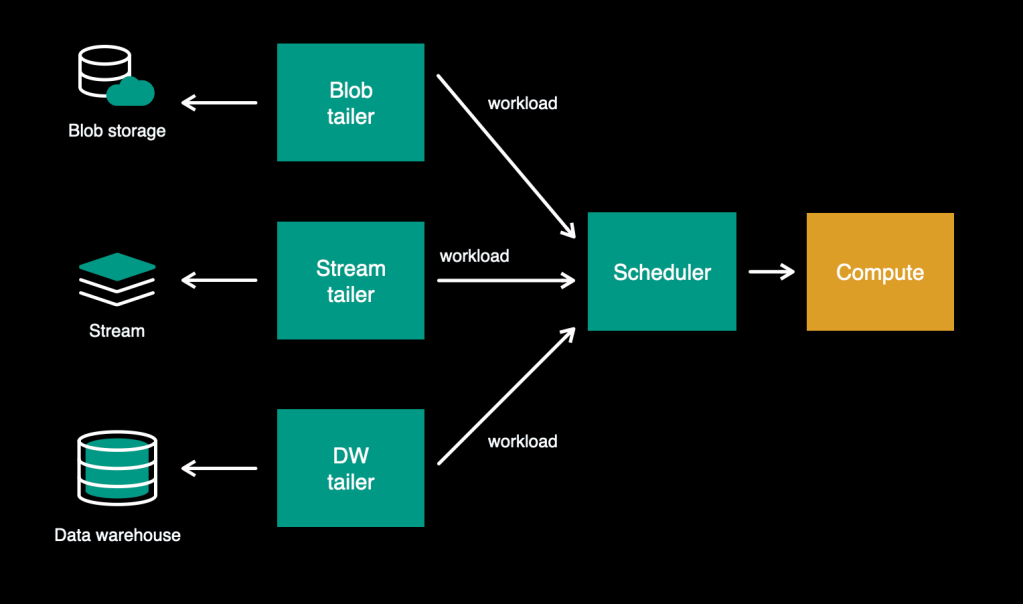
Each knowledge supply will be totally different—for instance, immutable vs. mutable, or fast-moving vs large-batch—and finally requires some particular code and settings to learn from it. We created adapters to deal with these “learn logic”–the varied mechanisms for studying totally different knowledge sources. These adapters act just like the UNIX tail command, tailing the information supply for brand spanking new workloads—so we name these “tailers.” In the course of the onboarding, for every knowledge supply that the client makes use of, the platform launches corresponding tailer situations for studying that knowledge.
With these modifications in place, our structure appears like this:
Push versus pull and penalties
To facilitate these modifications, the tailers have been now “push”-ing knowledge to the transport layer (the scheduler) as an alternative of the transport “pull”-ing it.
The advantage of this transformation was the flexibility to supply a generic scheduler API and make it data-source agnostic. In push-mode, tailers would ship the workloads as RPC to the scheduler and didn’t have to attend for ACK/NACK or lease timeout to know in the event that they have been profitable or failed.
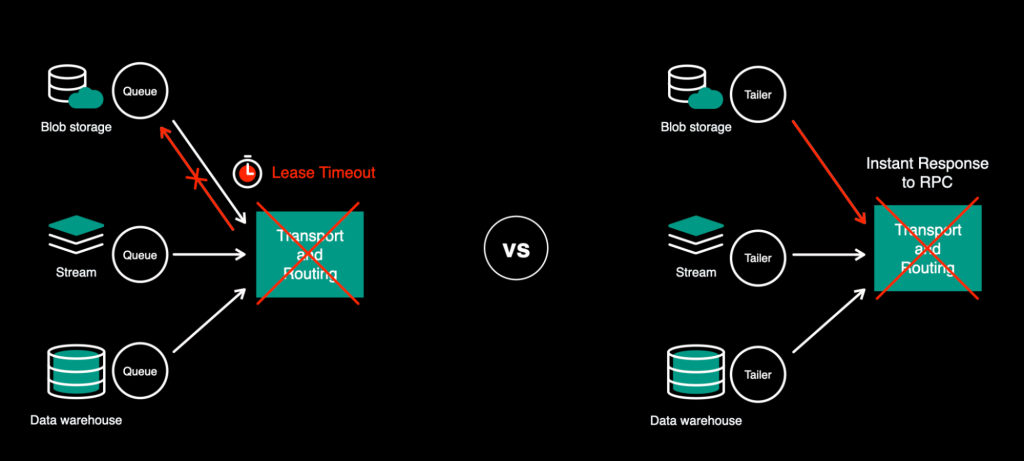
Cross-regional load balancing additionally turned extra correct with this transformation, since they might be managed centrally from the tailer as an alternative of every area pulling independently.
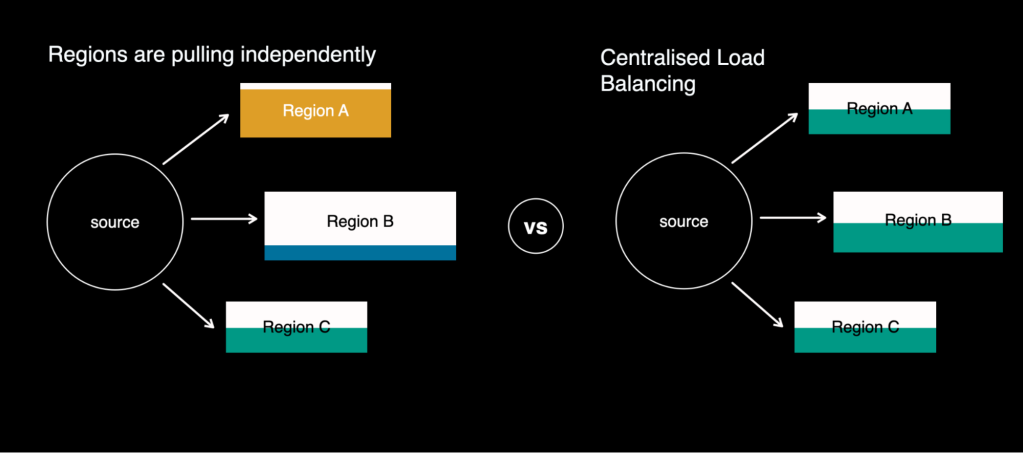
These modifications collectively improved the cross-region load distribution and the end-to-end latency of our platform, along with eliminating knowledge duplication (owing to buffering in FOQS) and treating all knowledge sources as first-class residents on our platform.
Nevertheless, there have been a few drawbacks to those modifications as properly. As push mode is basically an RPC, it’s not an amazing match for long-running workloads. It requires each consumer and server to allocate sources for the connection and maintain them throughout the complete perform working time, which might turn into a major downside at scale. Additionally, synchronous workloads that run for some time have an elevated likelihood of failure on account of transient errors that can make them begin over once more fully. Based mostly on the utilization statistics of our platform, nearly all of the workloads have been ending inside seconds, so it was not a blocker, but it surely’s necessary to contemplate this limitation if a major a part of your features are taking a number of minutes and even tens of minutes to complete.
Re-architecture: Outcomes
Let’s rapidly take a look at the primary advantages we achieved from re-architecture:
- Workloads are not getting copied in FOQS for the only real objective of buffering.
- Prospects don’t want to take a position further effort in constructing their very own options.
- We managed to interrupt down the system into granular parts with a clear contract, which makes it simpler to scale our operations and work on new options in parallel.
- Transferring to push mode improved our e2e latency and cross-regional load distribution.
By enabling first-class assist for varied knowledge sources, we have now created an area for additional effectivity wins because of the capacity to decide on probably the most environment friendly storage for every particular person use case. Over time we seen two common choices that prospects select: queue (FOQS) and stream (Scribe). Since we have now sufficient operational expertise with each of them, we’re at the moment able to match the 2 situations and perceive the tradeoffs of utilizing every for powering asynchronous computations.
Queues versus streams
With queue as the selection of storage, prospects have full flexibility in relation to retry insurance policies, granular per-item entry, and variadic perform working time, primarily because of the idea of lease and arbitrary ordering assist. If computation was unsuccessful for some workloads, they may very well be granularly retried by NACKing the merchandise again to the queue with arbitrary delay. Nevertheless, the idea of lease comes at the price of an inside merchandise lifecycle administration system. In the identical manner, priority-based ordering comes at the price of the secondary index on gadgets. These made queues an amazing common alternative with lots of flexibility, at a reasonable price.
Streams are much less versatile, since they supply immutable knowledge in batches and can’t assist granular retries or random entry per merchandise. Nevertheless, they’re extra environment friendly if the client wants solely quick sequential entry to a big quantity of incoming visitors. So, in comparison with queues, streams present decrease price at scale by buying and selling off flexibility.
The issue of retries in streams
Clogged stream
Whereas we defined above that granular message-level retries weren’t doable in stream, we couldn’t compromise on the At-Least-As soon as supply assure that we had been offering to our prospects. This meant we needed to construct the aptitude of offering source-agnostic retries for failed workloads.
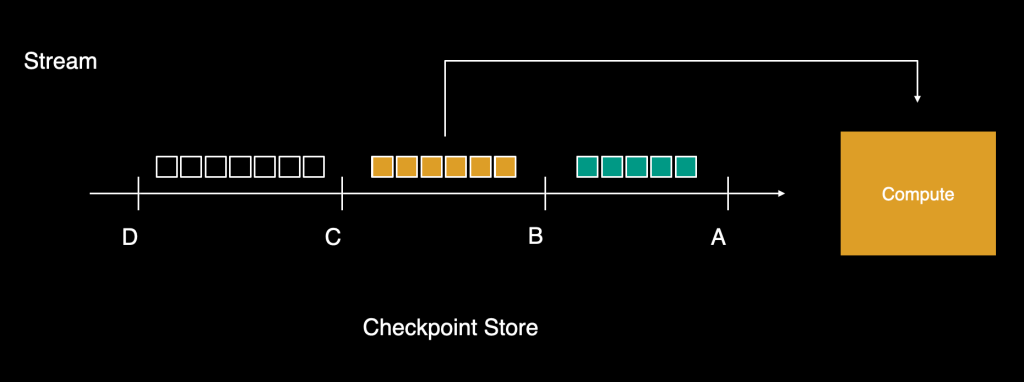
For streams, the tailers would learn workloads in batches and advance a checkpoint for demarcating how far down the stream the learn had progressed. These batches can be despatched for computation, and the tailer would learn the subsequent batch and advance the checkpoint additional as soon as all gadgets have been processed. As this continued, if even one of many gadgets within the final batch failed, the system wouldn’t be capable to make ahead progress till, after a couple of retries, it’s processed efficiently. For a heavy-traffic stream, this may construct up vital lag forward of the checkpoint, and the platform would finally battle to catch up. The opposite choice was to drop the failed workload and never block the stream, which might violate the At-Least-As soon as (ALO) assure.
Delay service
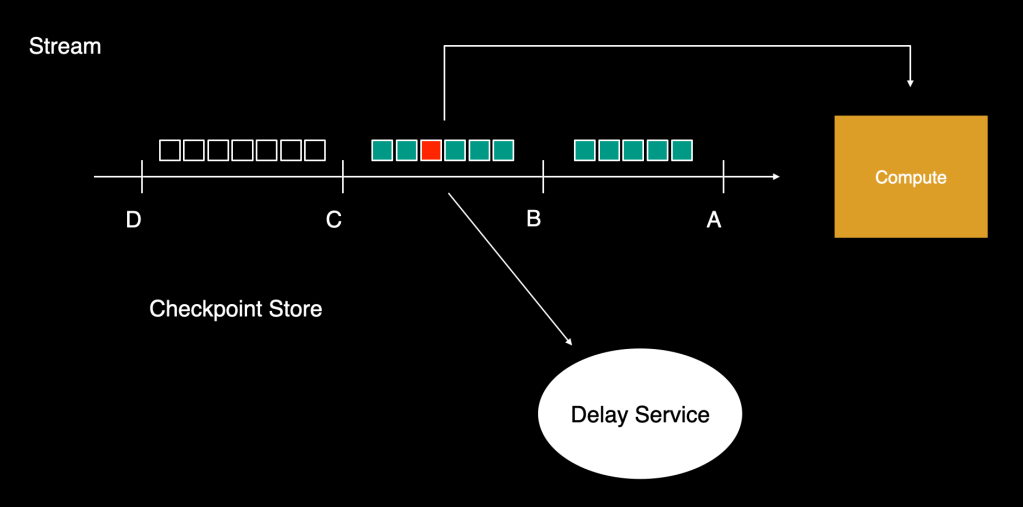
To unravel this downside, we have now created one other service that may retailer gadgets and retry them after arbitrary delay with out blocking the complete stream. This service will settle for the workloads together with their supposed delay intervals (exponential backoff retry intervals can be utilized right here), and upon completion of this delay interval, it’ll ship the gadgets to computation. We name this the controlled-delay service.
We now have explored two doable methods to supply this functionality:
- Use precedence queue as intermediate storage and depend on the idea that many of the visitors will undergo the primary stream and we are going to solely must take care of a small fraction of outliers. In that case, it’s necessary to ensure that throughout an enormous enhance in errors (for instance, when 100% of jobs are failing), we are going to clog the stream fully as an alternative of copying it into Delay service.
- Create a number of predefined delay-streams which might be blocked by a hard and fast period of time (for instance, 30s, 1 minute, 5 minutes, half-hour) such that each merchandise getting into them will get delayed by this period of time earlier than being learn. Then we will mix the accessible delay-streams to attain the quantity of delay time required by a particular workload earlier than sending it again. Because it’s utilizing solely sequential entry streams underneath the hood, this strategy can doubtlessly enable Delay service to run at a much bigger scale with decrease price.
Observations and learnings
The principle takeaway from our observations is that there is no such thing as a one-size-fits-all answer in relation to working async computation at scale. You’ll have to continually consider tradeoffs and select an strategy primarily based on the specifics of your explicit use circumstances. We famous that streams with RPC are finest suited to assist high-traffic, short-running workloads, whereas lengthy execution time or granular retries will likely be supported properly by queues at the price of sustaining the ordering and lease administration system. Additionally, if strict supply assure is essential for a stream-based structure with a excessive ingestion charge, investing in a separate service to deal with the retriable workloads will be helpful.